
Hello everyone! My (user)name is Anjosustrakr (Anjo for short), and I have been working on Duelyst II for the past few months with the aim of improving the AI. I am a Computer Science student, and this work was part of my senior thesis. I just got back from the IEEE Conference on Games, where I was lucky enough to be able to present my research on this game. My paper is not published yet, so here I will briefly explain what I have done so far, and (even more briefly) what I intend to do going forward.
The Previous AI
The previous AI was internally called the “starter AI,” and that is how I refer to it. The starter AI was programmed by the former Counterplay Games developer Lagomorph, who did a great job encoding it with expert knowledge. This must have been a painstaking process, as the starter AI consists of over 3,000 lines of code. The starter AI is known as an “expert rule-based player” because it follows a set of rules that were written by a domain expert (Lagomorph, in this case). For instance, one of these rules is to always replace at the beginning of the turn, and another set of rules tells the AI what card it should replace. There are also rules about how to play types of cards, like removal spells, and even some rules for specific cards that the AI would otherwise misplay.
For all the effort that went into the starter AI, it is still weak against humans, as you have probably experienced yourself. But for an AI only meant to play against new players, this was fine. The bigger problem was that the starter AI is inflexible. When cards are changed or added to the game, the AI does not know how to play with/against them unless new rules are added, which is overhead for developers. For instance, when Plasma Storm was changed to affect a 3×3 area instead of all minions with 3 or less Attack, the starter AI still assumed that it could play the card anywhere, but this could lead to it playing the card in useless or detrimental positions. When bosses were added, new rules had to be created for playing the boss cards.
My Approach
My goal was to create a flexible AI that did not require as much code as the starter AI, was a stronger player than the starter AI, and could still make decisions in a reasonable amount of time. To accomplish this, I implemented a few general-purpose planning algorithms and evaluated their winrate against the starter AI. To rapidly run these games, I used an AI vs AI experimentation framework that Lagomorph created to test his unreleased “phase II AI” (which has some bugs, so I could not test against it). This experimentation framework allows running headless games (no visuals or waiting for animations) with different AI versions fighting each other, which was invaluable to my research.
Background
All of the AI follow this template: given the current game state (the board and your hand and deck), they return an action to take in that state. An action can be choosing which cards to mulligan in the beginning of the game, moving a unit, attacking with a unit, playing a card somewhere, playing a follow-up (for multi-target cards), replacing a card, or ending the turn. Many states in Duelyst II have over 100 actions to consider and the action space is combinatorial (the same actions can be taken in a different order), which is a challenge for AI.
A fundamental concept in general-purpose planning is lookahead: simulating an action in a state to see what the resulting state would be. This requires copying the state and performing the action in the copy behind the scenes. Looking ahead enables planning around complex card abilities and interactions. Unfortunately, Duelyst II states are complex and thus slow to copy, which means that the amount of lookahead that can be done in a reasonable time is quite limited. For this reason, I stuck to only looking ahead until the end of the current turn (or sooner) in most of my algorithms. I did try some algorithms that simulated into the opponent’s turn (either looking at their actual deck or assuming that they have a deck of random faction cards) but did not find success with these approaches at the time, and they were way too slow.
Static Evaluator
Since I was not looking ahead to the end of the game, where a score is obvious (1 for win, 0 for tie, -1 for loss), I needed to create a function that would score any state so that the AI could compare them and know which action led to the best state. This is called a static evaluator. Creating a good static evaluator requires encoding some expert knowledge about what makes a good/bad board state, but nothing like the amount of knowledge needed for the starter AI. In comparison, the current iteration of the static evaluator is less than 300 lines of code, and the one I used for the following experiment was even shorter. I also made sure to make the static evaluator as general as possible so that it would not have the same pitfalls as the starter AI — it does not rely on information about specific cards, and the most specific it gets is having some knowledge about how certain keywords work. Here is roughly how it evaluates a state:
For end of game state:
- Win: 10,000 * winner Health
- Loss: -10,000 * winner Health
- Tie: 0
For any other state:
- [Total value of allied units, equipped artifacts, and cards in hand] – [the same total for enemy stuff]
- I estimate a unit’s total value in terms of stat points based on their mana cost and then subtract their original stats to calculate their ability value, then add that to their current stats to get their current value
- Units get a bonus for being near enemies they can kill and a penalty for being far from mana orbs
- Value of an artifact includes durability
- Value of a card in hand is 1 (the AI does not look at your hand beyond to count the cards, don’t worry)
Algorithms
These were some of the algorithms I implemented:
- Random: Takes a random action.
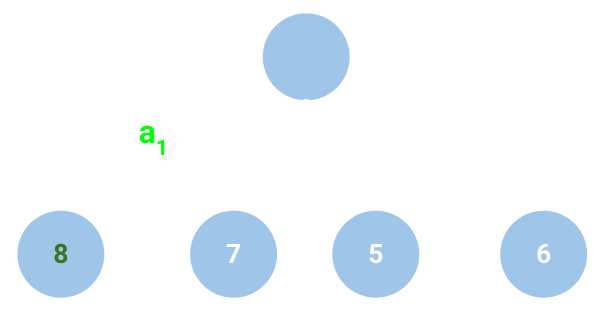
- Greedy: Does one-step lookahead — tries all actions and picks the action that leads to the next state with the highest value (according to the static evaluator). The following picture shows the Greedy approach — the blue circles represent states, the arrows are actions, the top circle is the current state, and the numbers in the states are their values.
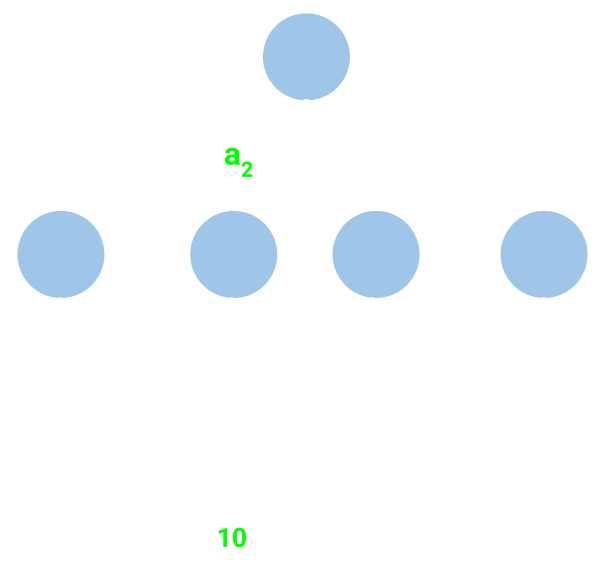
- Rollout: Same as Greedy but does a constant number of rollouts from each next state. This means that it continues simulating, either taking random actions or following the Greedy strategy, until the end of the turn, repeats this a constant number of times from the same initial state, then takes the average of the end-of-turn state values and returns that to represent how good the original action is. The following picture shows Rollout with 1 rollout per next state.
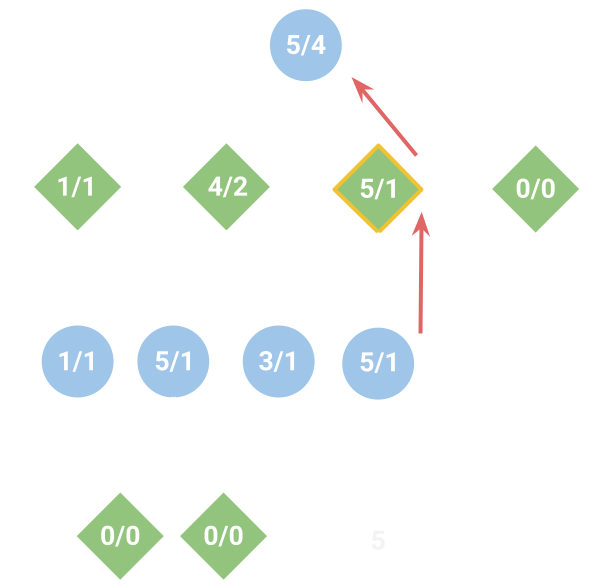
- Monte Carlo Tree Search (UCT): Sorry, I don’t feel like explaining this one in detail, but Wikipedia is always helpful if you’re interested. This is the algorithm that is used for most strong game AI (with some enhancements), including AlphaGo. In the picture below, the blue circles are state nodes and the green diamonds are action nodes. The first number in a node is the value and the second is the visit count. A tree of these nodes is iteratively built within a certain time limit, with one node being added per simulation from the current state node (at the top). After a node is added, a rollout (Random or Greedy) is done from it, and the resulting value is backpropagated up the tree (red arrows). Then, after planning time is up, the action with the highest value (outlined in yellow) is chosen. The important thing here is that UCT looks ahead several actions without just doing a rollout and tries out different possibilities. It balances exploring new actions with doing more simulations in the current best-looking actions.
Results
Here are the results of each of the above algorithms (some with different settings for rollouts, which are in parentheses) playing 1,000 games against the starter AI (both players use the Lyonar AI deck). The first plot shows average winrate:
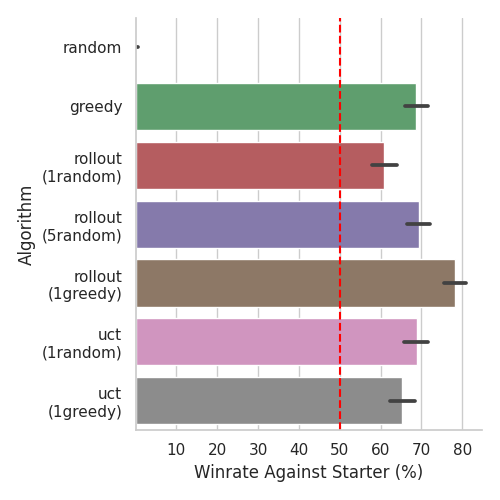
As you can see, every algorithm except poor Random gets 60-80% winrate against the starter AI. UCT is limited to 5 seconds of planning before choosing an action, which is why it does not perform the best. Greedy, the second-simplest algorithm, does quite well, but Rollout with greedy rollouts is the clear winner.
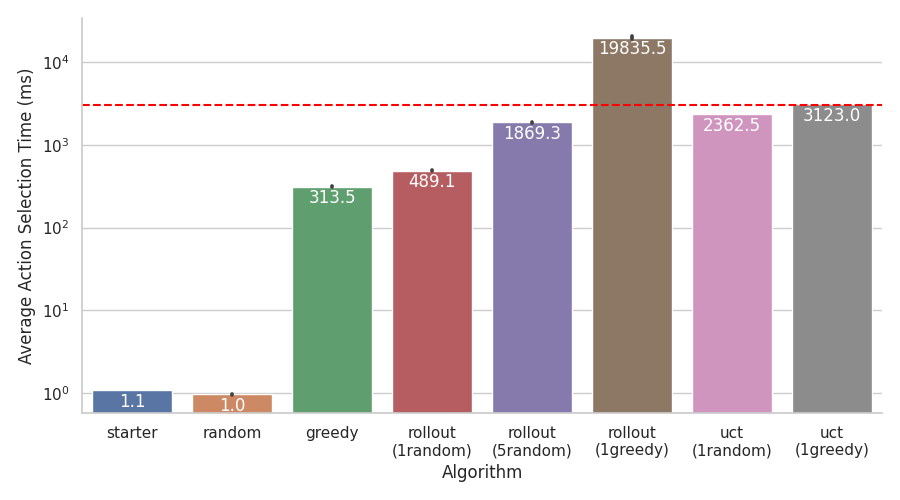
This plot shows the average time each algorithm takes to choose an action. The algorithm that got the best winrate also takes a whopping 20 seconds per action, which of course cannot go in the game. Greedy performed well and only takes 300 milliseconds per action, which is pretty fast (although slow in comparison to the starter AI at 1 millisecond).
The New AI
The above plots show why Greedy was the best choice for replacing the starter AI. Although other algorithms were stronger, they took much too long for the actual game. The problem with planning is that it requires fast state copying to be very good, and Duelyst II does not have fast state copying.
In any case, I converted Greedy into Greedy+ in collaboration with Stimulant, and this algorithm is what has replaced the starter AI in the game. Greedy+ features the following changes:
- Simple rule-based mulligan. Greedy just mulligans randomly because all cards in hand look the same to it.
- Simple rule-based replace at beginning of turn. Greedy replaces randomly and at random times.
- Simple lethal checking. If the AI has minions nearby the enemy General that can kill them, it gives more value to enemy General Health and allies near the enemy General to encourage killing them (or discovering that it was a false alarm) before doing anything else.
- Action queuing. Instead of having a small wait before taking each action, it searches ahead to find the actions until a random action or the end of the turn and then sequentially executes the actions it planned without delay. This means that the wait time at the beginning of the turn after replacing could be a few seconds in some states, just as it might be for a human player.
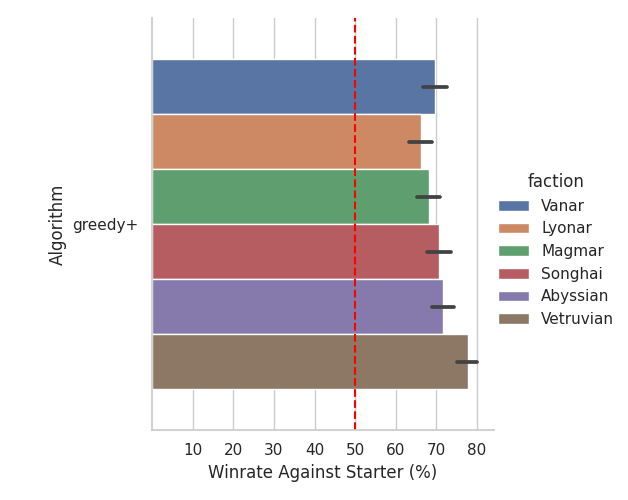
Here are the results of Greedy+ playing 1,000 games against the starter AI with both players using the same AI faction deck:
What’s Next?
Although I graduated with my B.S. degree, I am continuing on to get an M.S. in Computer Science this year, and my master’s thesis is going to be on AI for Duelyst II! My goal for this project is to end up with an intermediate-level (or strong) player, and I will be using machine learning and reinforcement learning to do so. You have not heard the last of me!
About the Author
Anjo’s favorite factions are Songhai and Vetruvian. He designed the Kaleos, Reborn boss battle (but all implementation credit goes to Stimulant), so if you hate it, you know who to blame. He likes reading, writing, making/playing games, cats, serpenti, and self-advertisement. He has published a few games, including the physical card game Lesser Evil and the web game The Thirsty Games. But Duelyst II is the only game you need in your life, so why even bother checking them out?